Verbalized Sampling: More Diversity Without Fine-Tuning
Verbalized Sampling (VS) is a prompt-based trick to fight Mode Collapse in aligned LLMs—getting you more creative answers without any training.
There’s this weird paradox with modern language models: They’re capable of remarkable range, yet they often sound like they’ve all agreed on a single, “sensible” voice. Friendly. Balanced. Risk-averse. And let’s be honest: predictable.
Researchers have a name for this: Mode Collapse. It doesn’t mean the model is broken. It means that after alignment (like RLHF), it slips into the same answer mode way too often—especially when there are actually tons of equally good ways to respond: creative writing, dialogue, open questions, brainstorming.

A paper from October 2025 gives this a name: Typicality Bias. When human preference data favors “typical,” familiar phrasing, the model eventually learns to reward exactly that: the middle ground, the expected, the stuff that sounds “nice.” The edges of the distribution—the interesting variations—get flattened out. It’s alignment as a cultural smoother. Source: arXiv:2510.01171
Verbalized Sampling is a prompting technique from the October 2025 paper arXiv:2510.01171. Instead of returning one answer, the model produces a weighted set of possible answers. In creative-writing experiments, this increased output diversity by 1.6x to 2.1x, with two to five times the token use. More capable models benefited more.
The Idea Behind Verbalized Sampling
The fix proposed by the paper is almost annoyingly simple: Verbalized Sampling (VS) is a training-free prompting technique. Instead of saying “Give me an answer,” you ask the model for a small distribution of answers.
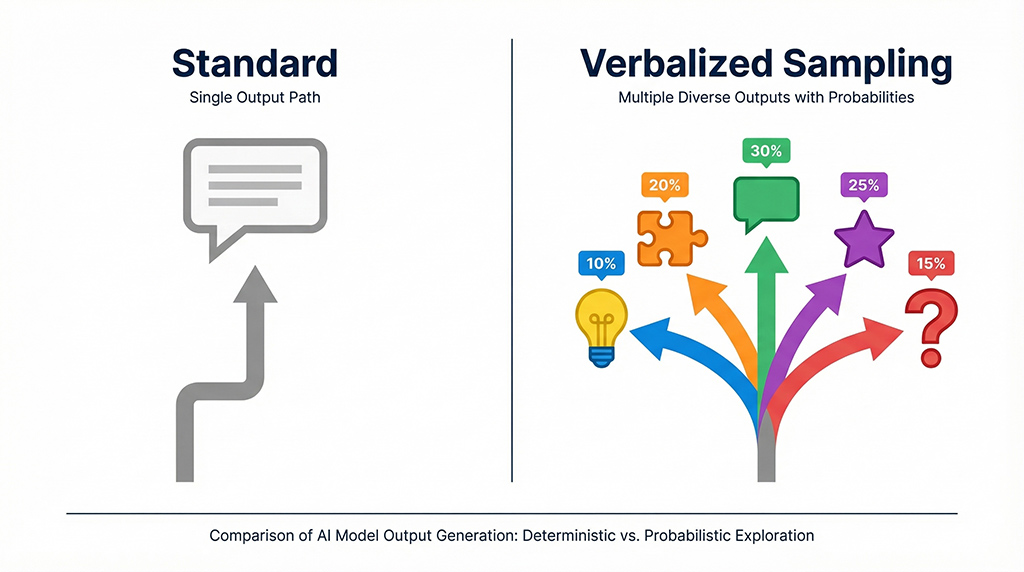
The core trick: You ask the model not just to list options, but to describe them as a probability space. This shifts the task—away from “give me the safest single answer” to “show me plausible alternatives, even the less likely ones.”
In the paper, it sounds something like this: “Generate 5 answers and their respective probabilities, including low-probability variants.” In experiments, diversity in creative writing tasks jumped by 1.6x to 2.1x, without sacrificing quality or safety. Source: arXiv:2510.01171
Important note: These “probabilities” aren’t the actual token probabilities in most products; they’re a useful self-description. The value lies less in the numerical accuracy and more in the perspective shift it forces.
Why It Actually Works
From a workflow perspective, VS feels like a lever against the built-in “be careful” reflex of many models. You’re forcing the system to show more of what it already knows but wouldn’t usually play as its first card.
The paper also reports that more capable models benefit even more from VS. That fits the intuition: The larger the internal possibility space, the more it pays to actually tap into it. Source: arXiv:2510.01171
Three VS Prompts I Would Actually Use
1) Creativity Without the Fluff
You are a precise, creative assistant.
Generate 5 different answers to the question and assign a probability to each (Sum = 1.0).
Include at least 2 low-probability but plausible options.
Question: What is an unusual opening for an essay on digital fatigue?2) Open Questions, Less “Cookie-Cutter” Answers
Generate 5 plausible answers with probabilities (Sum = 1.0).
Explicitly mark uncertainties.
Question: Why do many knowledge management tools fail in small teams?3) VS-CoT for Tougher Tasks (Use Sparingly)
Think step-by-step.
Generate 5 solution approaches with probabilities.
Then choose one approach and deliver the final answer briefly and clearly.
Task: Design an experiment to measure Mode Collapse in chatbots.(Variants like VS-CoT are also discussed around the paper, for instance in the OpenReview entry and community summaries. Source: OpenReview)
Limits and Side Effects
VS isn’t a magic wand; it’s an inference-time trade-off:
- Token Costs: You’re generating multiple candidates. That often costs 2x to 5x more tokens, depending on the setting.
- Pseudo-Precision: The numbers are sometimes more “calibrated storytelling” than real model probability.
- Safety Still Matters: VS is meant to increase diversity, not bypass guardrails. Good prompts keep clear boundaries.
If you’re looking for alternatives that require less “multi-output,” classic sampling parameters (top-p, temperature) or structured multi-perspective prompts are often the next step. VS is particularly strong when the model has a wide internal possibility space but alignment keeps pushing it toward the same output — exactly the case described in the paper for capable models.
Practical links to get started:
- Paper: arXiv:2510.01171
- Project Page: verbalized-sampling.com
- Code/Material: GitHub: CHATS-lab/verbalized-sampling